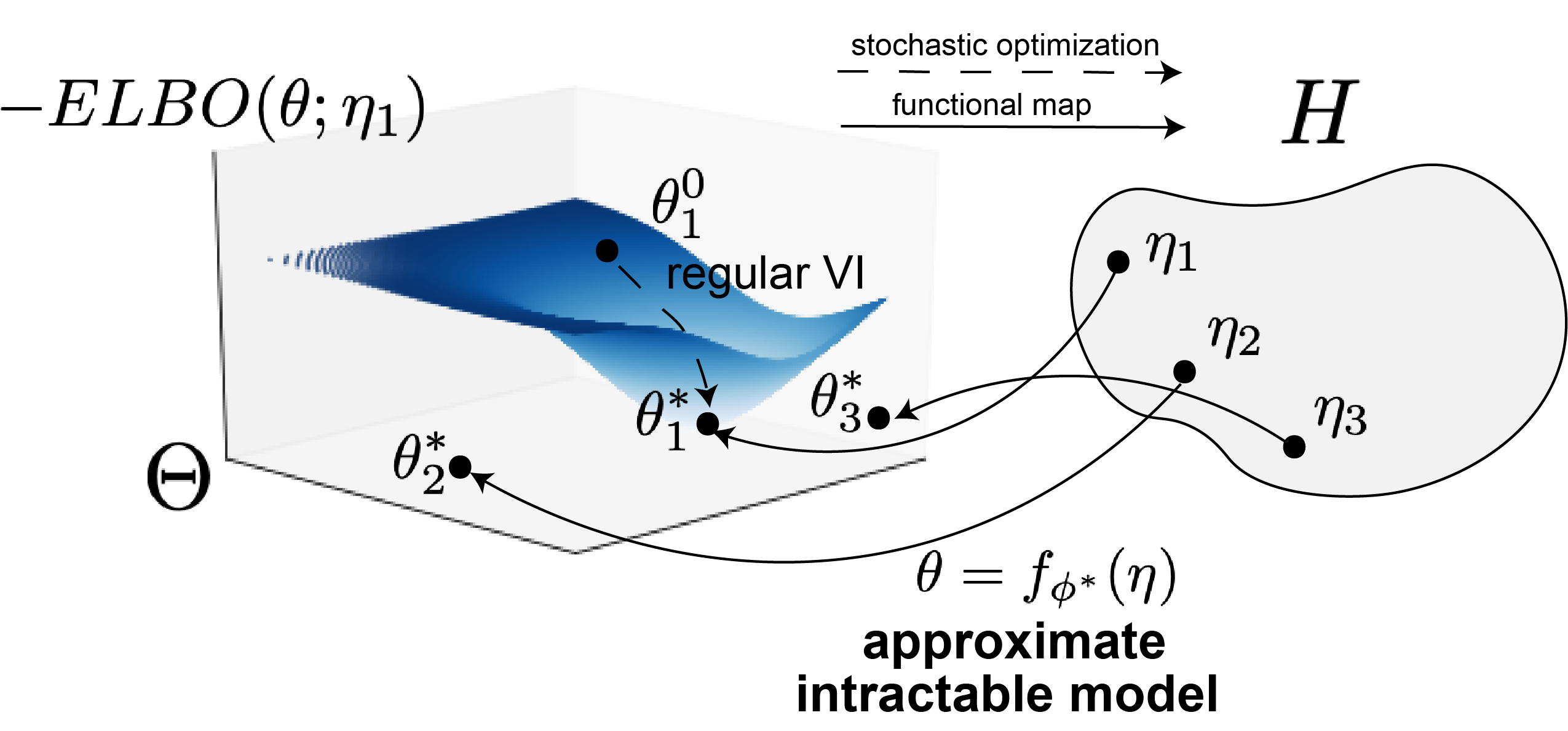
Introduction
Many models used in machine learning are intractable exponential families. Inference in intractable exponential families incurs some computational cost, often that of stochastic optimziation through variational inference. We introduce a deep generative two-network architecture called exponential family networks (EFNs, Bittner et al. 2019) for learning intractable exponential family models (not single distributions). EFNs learn a smooth function mapping natural parameters to optimal variational parameters .
Background
Why exponential families?
Exponential family models have the form
with natural parameter , sufficient statistics , base measure , and log normalizer .
Side note: As we go on, we “suppress” the base measure , since we can simply re-write the exponential family moving into the sufficient statistics vector by taking its . Thus, in this representation, the natural parameter vector also implicitly has a concatenated 1 just as the sufficient statistics have a concatenated .
We focus on the fundamental problem setup of Bayesian inference, which is conditionally iid draws of data points given a global latent variable .
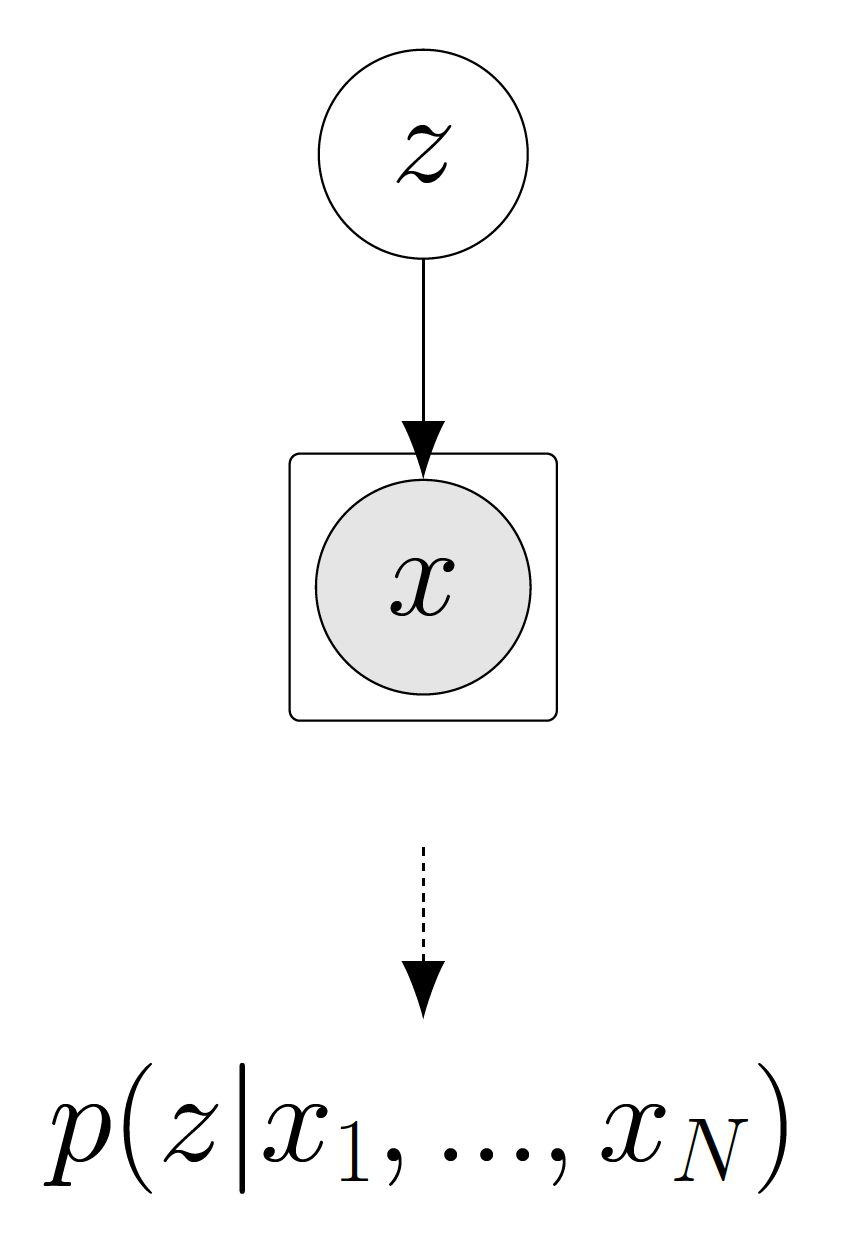
With an exponential family likelihood
and prior
the posterior has the form:
Notice that the natural parameters of the posterior of such exponential family models are comprised of the natural parameter of the prior , the sum of the sufficient statistics of the data points , and a final element . Notice a key observation that the dimensionality of the natural parameter of the posterior does not change with the the number of data points sampled. From the Pitman, Koopman, Darmois Theorem, we know that only models with exponential family likelihoods have this property.
Exponential family networks
EFNs are comprised of two networks, the density network: and the parameter network
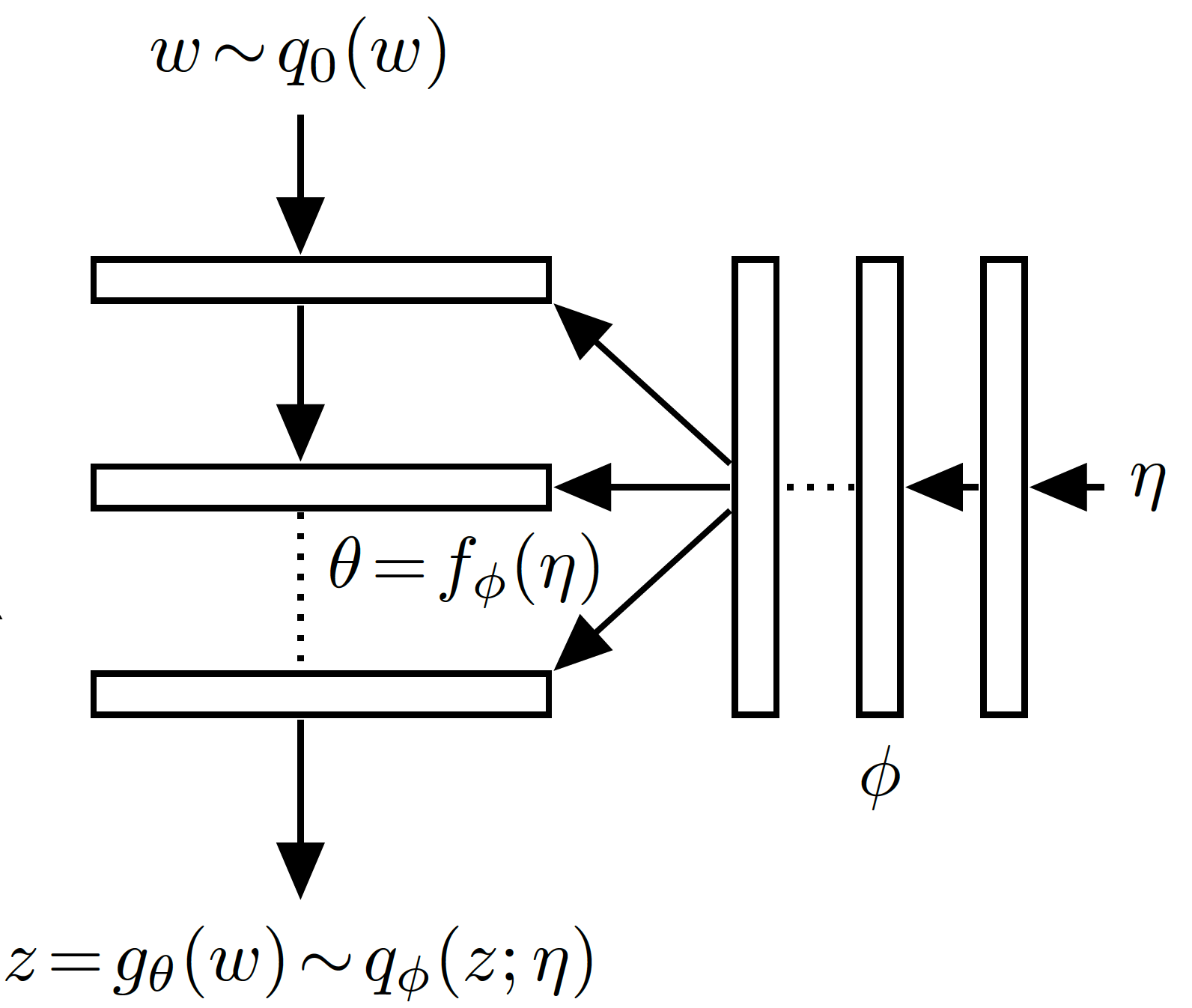
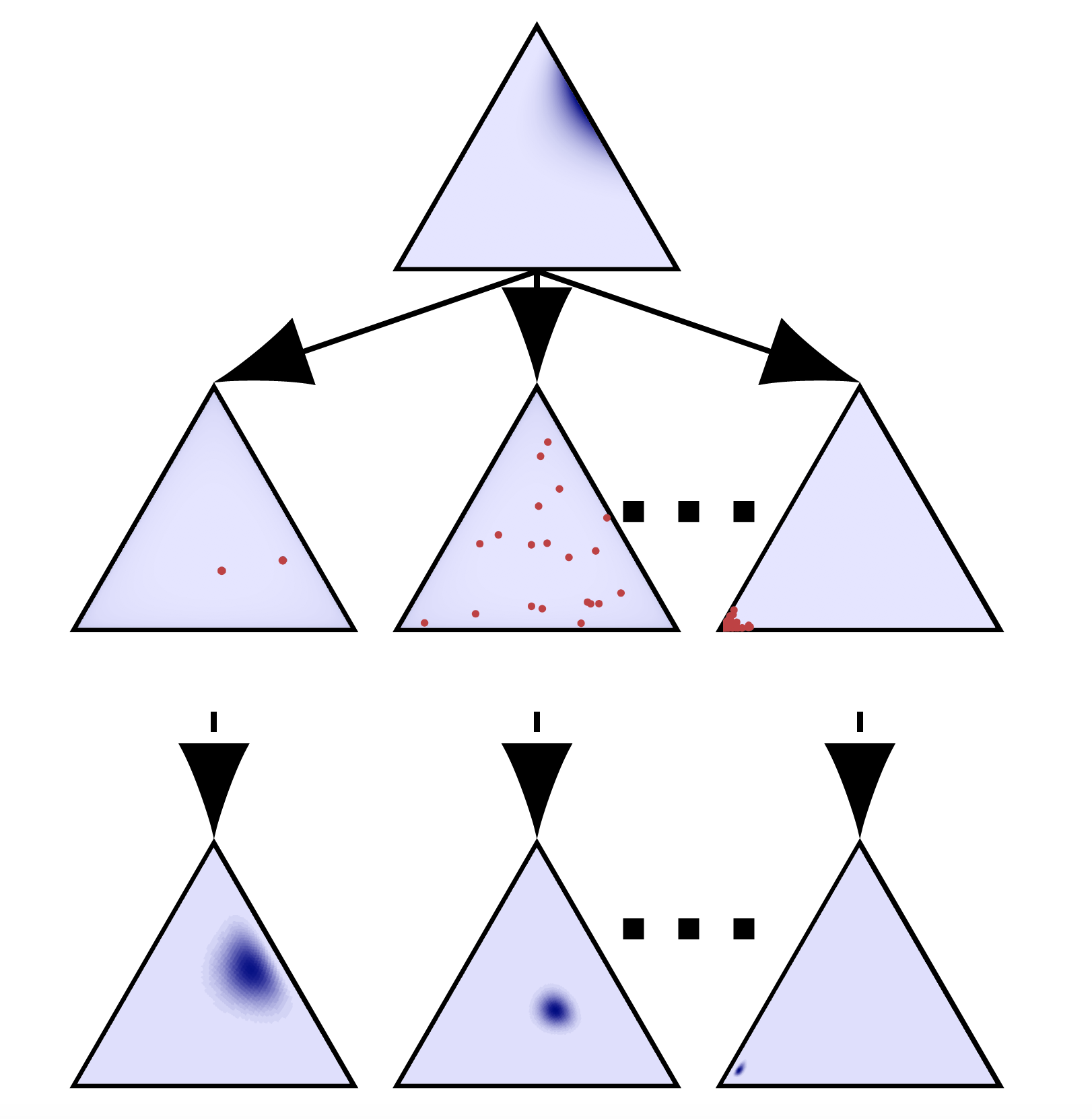
The parameter network (horizontal) is a fully connected neural network mapping . EFNs learn approximations of exponential family models , so that , where
For a given , we minimize the KL divergence between the indexed distribution of and .
We do this over a desired prior distribution ,
which corresponds to the loss below.
Example: HD
Sean Bittner June 18, 2019
References
Bittner, Sean R., and John P. Cunningham. “Approximating exponential family models (not single distributions) with a two-network architecture.” arXiv preprint arXiv:1903.07515 (2019).